Der O-Kalkül, Aufwand von Algorithmen
Hat man einen Algorithmus konstruiert, so möchte man wissen wie schnell oder effizient dieser seine Aufgabe erledigt. Eine Methode, dies zu berechnen, liefert der O-Kalkül.
Hierzu betrachtet man einen Umfang von Eingabedaten (die wir mit bezeichnen), und untersuchen wie sich die Laufzeit des Algorithmus verhält wenn man stark vergrössert. Konstante Faktoren sind bei dieser Betrachtung nicht von Interesse, da Rechner um konstante Faktoren in ihrer Geschwindigkeit variieren.
Definition
Es gelten folgende Definitionen der Funktionenklassen:
Mit Hilfe dieser Definitionen kann man leicht beschreiben, ob ein Algorithmus höchstens (), mindestens () oder gleich () stark wie wächst.
Abschätzungen
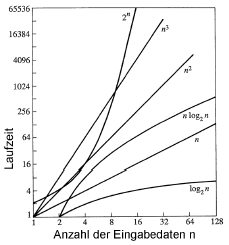
Betrachtet man nun den Aufwand eines Algorithmus, so ist immer der Teil der Ausschlaggebende, der am stärksten wächst; Konstanten werden wie vorher schon gesagt einfach weggelassen. Für einen Algorithmus mit Aufwand betrachten wir also nur den Teil. Somit ergeben sich die folgenden, wichtigen Abschätzungen:
| -Notation | Aufwand |
|---|---|
| Konstanter Aufwand | |
| Logarithmischer Aufwand | |
| Linearer Aufwand | |
| Quasilinearer Aufwand | |
| Quadratischer Aufwand | |
| Polynomialer Aufwand | |
| Exponentieller Aufwand | |
| Ganz ganz böse… |
Am besten ist natürlich, wenn man es schafft seinen Algorithmus so zu konstruieren, dass er einen Aufwand von hat. Ab wird es ungemütlich, und alles was darüber hinausgeht sollte tunlichst vermieden werden. Um zu illustrieren warum, ist hier eine Tabelle wieviel Daten ein Algorithmus einer bestimmten Klasse bei gleichbleibender Zeit verarbeiten kann, wenn die Rechner um den Faktor schneller werden:
| bis (für große ) | |
| (für ) |
Rekurrenzen / Rekursion
Rekurrenzen treten dann auf, wenn ein Algorithmus sich selbst aufruft. Den Aufwand solcher Algorithmen zu bestimmen kann etwas schwieriger sein. Es gibt jedoch eine „Master-Methode“, wenn sich der Aufwand des Algorithmus durch folgende Form beschreiben lässt:
Es seien , und eine Funktion. Es sei folgende Rekurrenz gegeben:
Dann gelten diese Regeln:
Die meisten Rekurrenzen werden durch diese Methode abgedeckt. Hat man jedoch sehr abgefahrene rekursive Algorithmen, so gibt es noch den allgemeinen Beschleunigungs- und Aufteilungssatz:
Es vermag:
wobei , , für
Dann gilt:
Es sollte klar sein, dass es immernoch Rekurrenzen geben kann, die sich nichtmal mit diesem Satz lösen lassen. Da hilft dann nurnoch raten, oder ein anderes Verfahren (z.B. generierende Funktionen).